Kafka to Postgresql
3 minute read
Kafka-to-postgresql is a microservice responsible for consuming kafka messages and inserting the payload into a Postgresql database. Take a look at the Datamodel to see how the data is structured.
This microservice requires that the Kafka Topic umh.v1.kafka.newTopic exits. This will happen automatically from version 0.9.12.
How it works
By default, kafka-to-postgresql sets up two Kafka consumers, one for the High Integrity topics and one for the High Throughput topics.
The graphic below shows the program flow of the microservice.
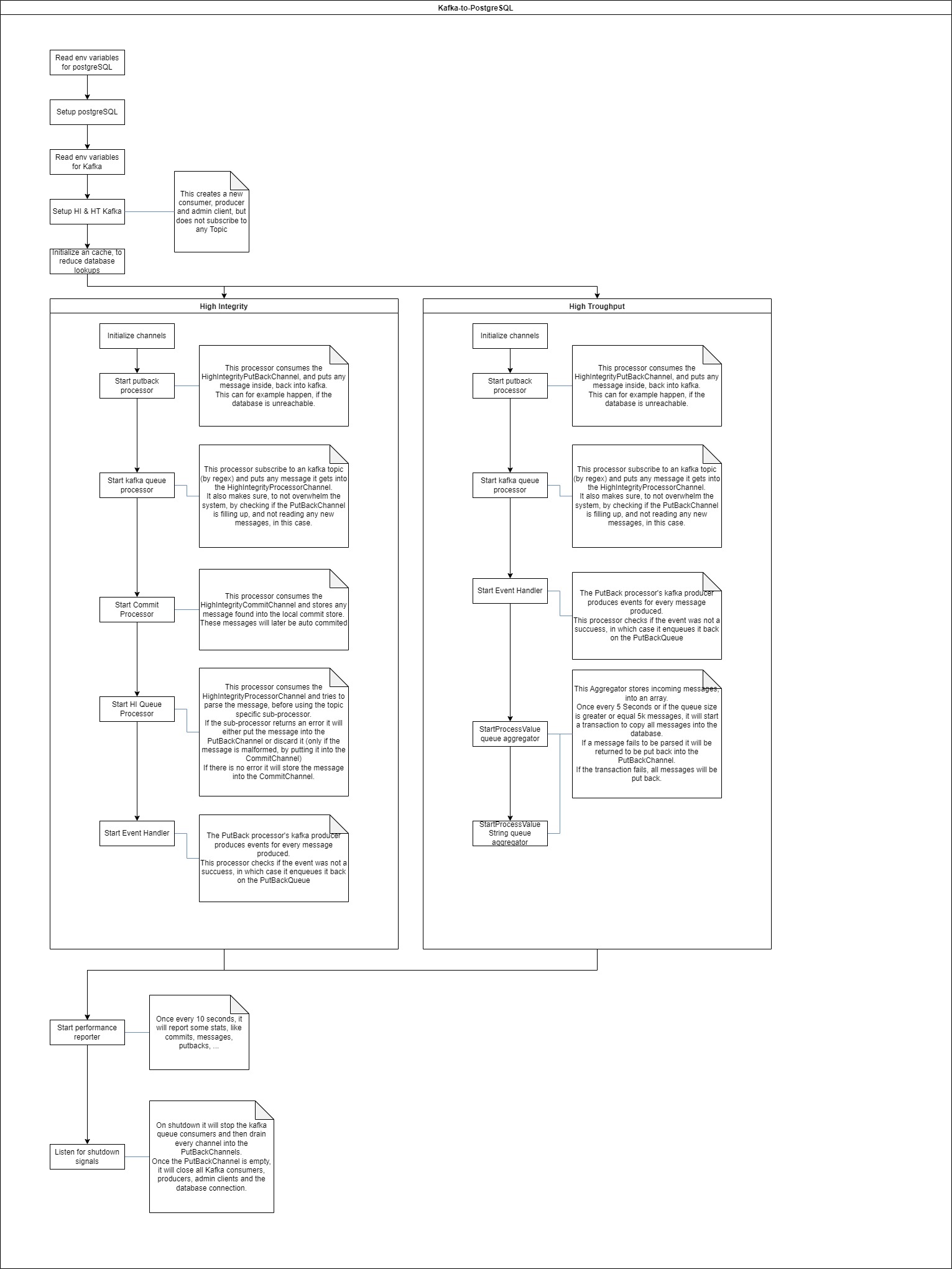
High integrity
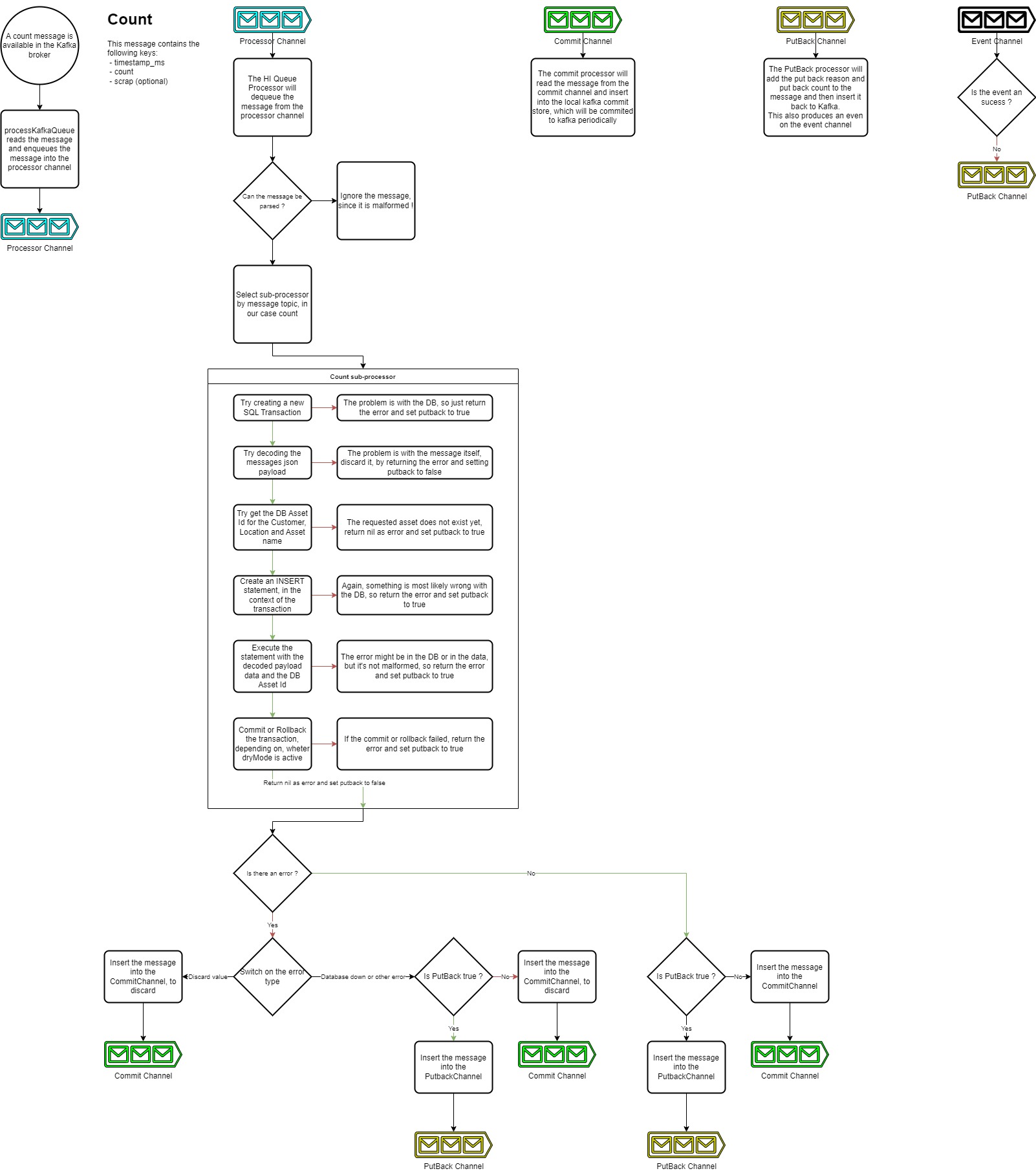
The High integrity topics are forwarded to the database in a synchronous way. This means that the microservice will wait for the database to respond with a non error message before committing the message to the Kafka broker. This way, the message is garanteed to be inserted into the database, even though it might take a while.
Most of the topics are forwarded in this mode.
The picture below shows the program flow of the high integrity mode.
High throughput
The High throughput topics are forwarded to the database in an asynchronous way. This means that the microservice will not wait for the database to respond with a non error message before committing the message to the Kafka broker. This way, the message is not garanteed to be inserted into the database, but the microservice will try to insert the message into the database as soon as possible. This mode is used for the topics that are expected to have a high throughput.
The topics that are forwarded in this mode are processValue , processValueString and all the raw topics.
Kubernetes resources
- Deployment:
united-manufacturing-hub-kafkatopostgresql - Secret:
united-manufacturing-hub-kafkatopostgresql-certificates
Configuration
You shouldn’t need to configure kafka-to-postgresql manually, as it’s configured
automatically when the cluster is deployed. However, if you need to change the
configuration, you can do it by editing the kafkatopostgresql section of the Helm
chart values file.
Environment variables
| Variable name | Description | Type | Allowed values | Default |
|---|---|---|---|---|
DEBUG_ENABLE_FGTRACE | Enables the use of the fgtrace library. Not reccomended for production | string | true, false | false |
DRY_RUN | If set to true, the microservice will not write to the database | bool | true, false | false |
KAFKA_BOOTSTRAP_SERVER | URL of the Kafka broker used, port is required | string | Any | united-manufacturing-hub-kafka:9092 |
KAFKA_SSL_KEY_PASSWORD | Key password to decode the SSL private key | string | Any | "" |
LOGGING_LEVEL | Defines which logging level is used, mostly relevant for developers | string | PRODUCTION, DEVELOPMENT | PRODUCTION |
MEMORY_REQUEST | Memory request for the message cache | string | Any | 50Mi |
MICROSERVICE_NAME | Name of the microservice (used for tracing) | string | Any | united-manufacturing-hub-kafkatopostgresql |
POSTGRES_DATABASE | The name of the PostgreSQL database | string | Any | factoryinsight |
POSTGRES_HOST | Hostname of the PostgreSQL database | string | Any | united-manufacturing-hub |
POSTGRES_PASSWORD | The password to use for PostgreSQL connections | string | Any | changeme |
POSTGRES_SSLMODE | If set to true, the PostgreSQL connection will use SSL | string | Any | require |
POSTGRES_USER | The username to use for PostgreSQL connections | string | Any | factoryinsight |